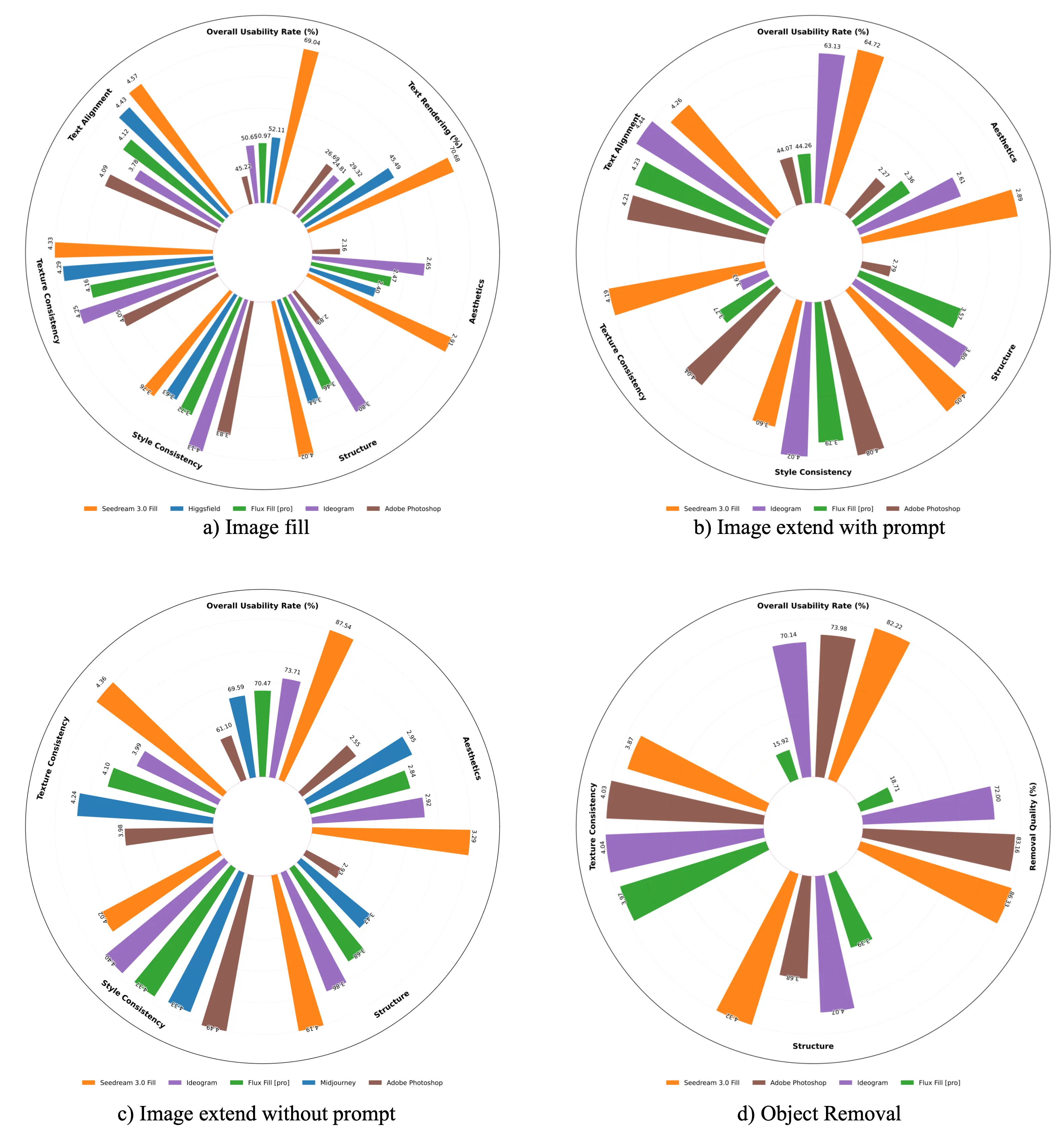
Overall evaluation for Seedream 3.0 Fill across four image editing tasks, and text rendering is include in image fill.
In this paper, we introduce OneReward, a unified reinforcement learning framework that enhances the model’s generative capabilities across multiple tasks under different evaluation criteria using only One Reward model.
By employing a single vision-language model (VLM) as the generative reward model, which can distinguish the winner and loser for a given task and a given evaluation criterion, it can be effectively applied to diffusion-based models, particularly in contexts with varied data and diverse task objectives. We utilize OneReward for mask-guided image generation, which can be further divided into several sub-tasks such as image fill, image extend, object removal, and text rendering, involving a binary mask as the edit area. Although these domain-specific tasks share same conditioning paradigm, they differ significantly in underlying data distributions and evaluation metrics.
Existing methods often rely on task-specific supervised fine-tuning (SFT), which limits generalization and training efficiency. Building on OneReward, we develop Seedream 3.0 Fill, a mask-guided generation model trained via multi-task reinforcement learning directly on a pre-trained base model, eliminating the need for task-specific SFT. Experimental results demonstrate that our unified edit model consistently outperforms both commercial and open-source competitors, including Ideogram, Adobe Photoshop, and FLUX.Fill [Pro], across multiple evaluation dimensions.
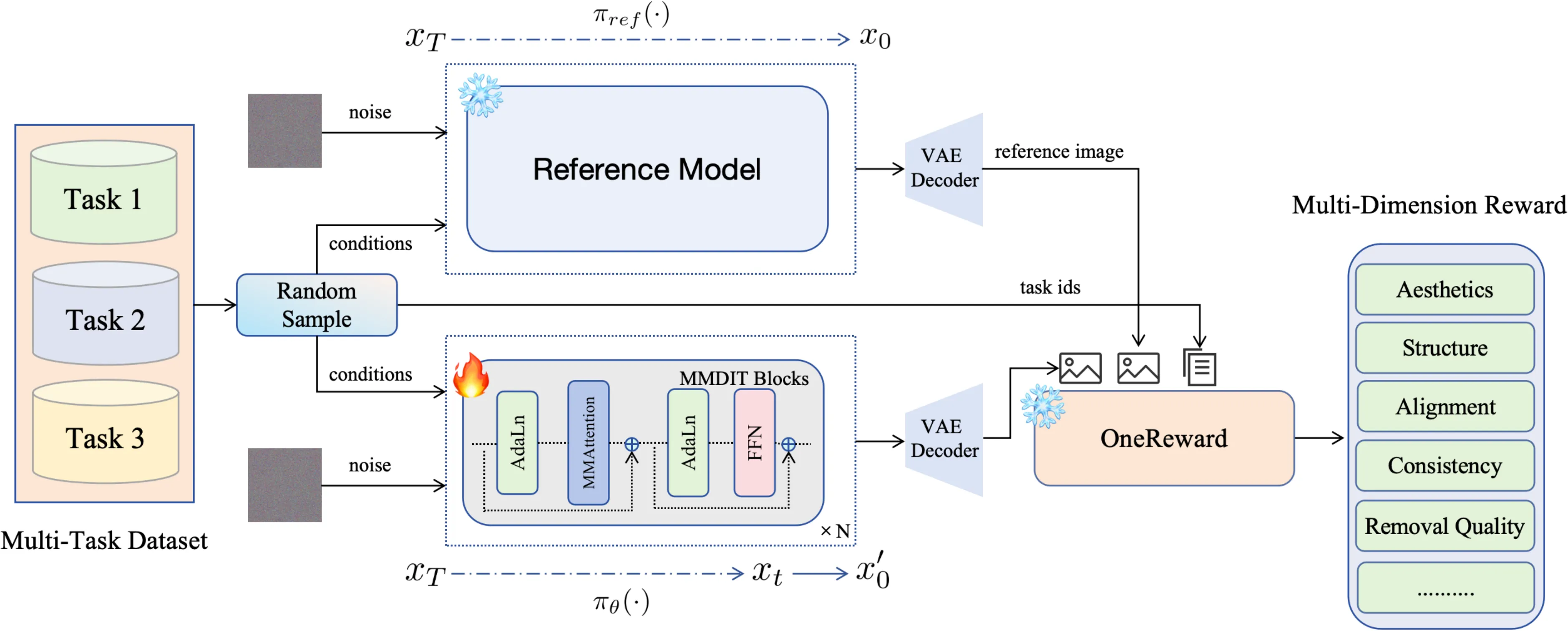
RL Pipeline: Overall pipeline of our unified RL procedure. We first random sample image and conditions from different task with a certain probability. Start with same condition and different init noise, the reference image is fully denoised using the reference model, denoted as πref(⋅). While the evaluation image is partially denoised with randomly selected step and directly predict x0′ based on the policy model, denoted as πθ(⋅). The reward model guides learning by encouraging the policy model to achieve superior performance to the reference model across all evaluation dimensions and tasks.
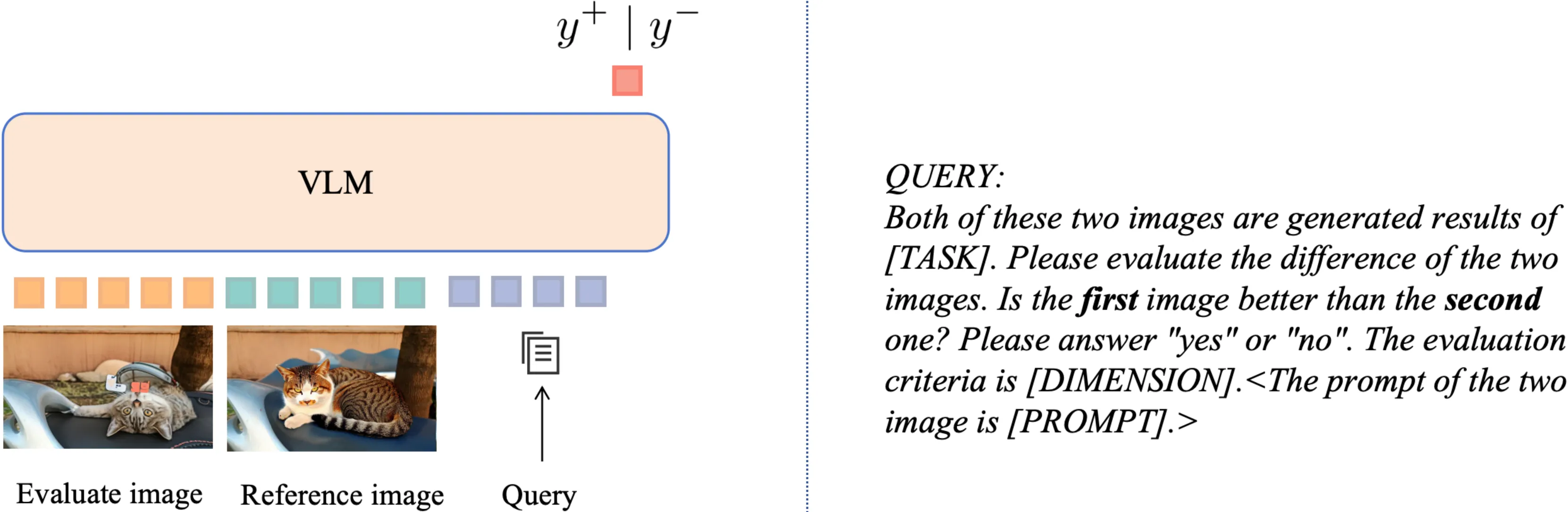
Reward Model: The detail of our one reward model. We utilize VLM to judge whether the first image is better than the second one. In the process of reward feedback learning, the probability of y+ token is treated as the reward to the diffusion models. We simplely add the edit task and the evaluation dimensions to the user query, achieving the goal of training for different task and dimensions. The content of angle brackets is optional, only add when the evaluation dimension is Text Alignment.
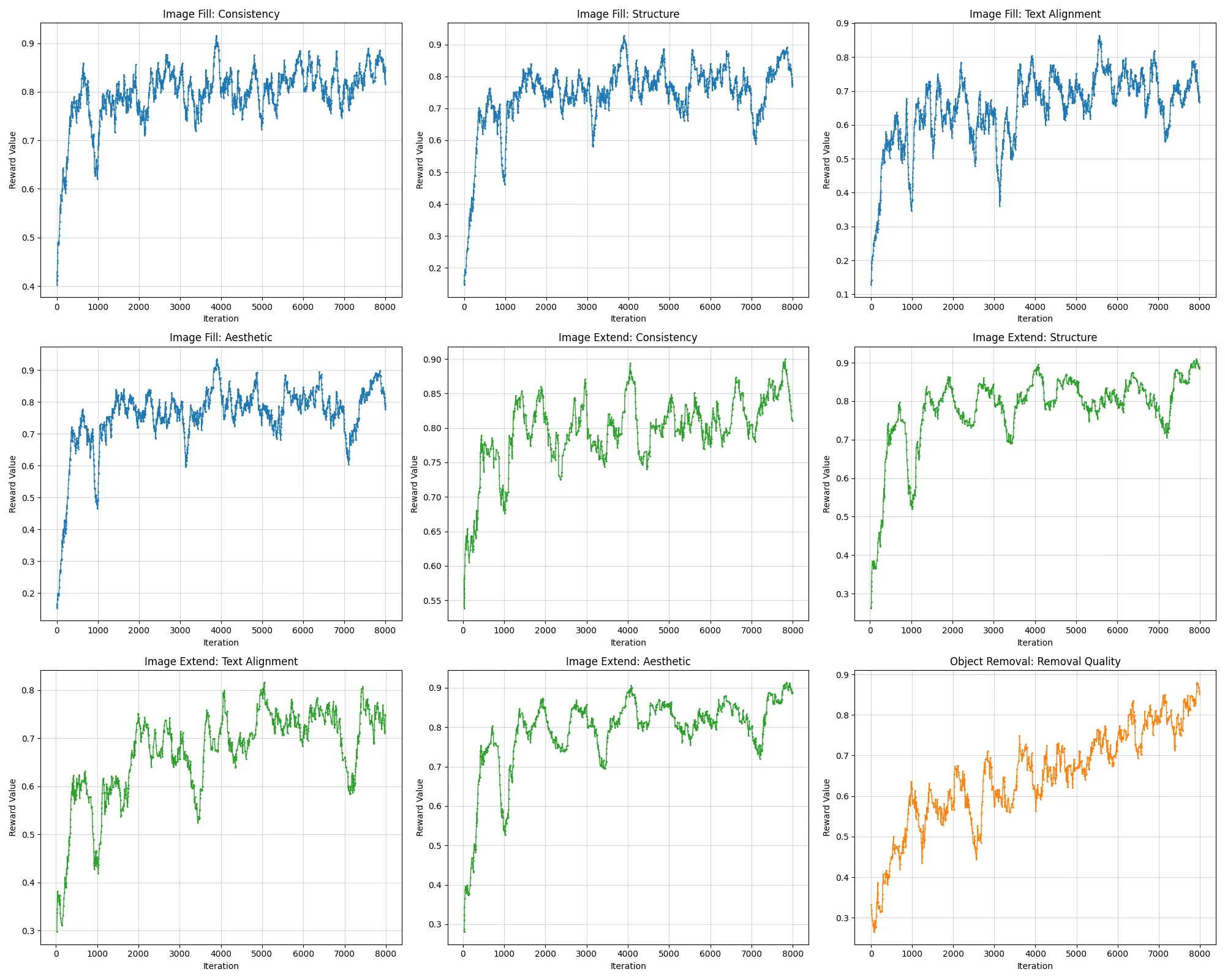
Reward Curve: We visualize the reward curves of Consistency, Structure, Text Alignment, Aesthetics for image fill(blue) and image extend(green), Removal Quality for object removal(orange).


straw hat


Canton Tower


Temple of Heaven


Kimono


a cat


a big sunflower


girl on a bicycle


red wedding dress


















colorful hot air balloon


cable car


Two burgundy Chinese style lanterns


holding a bouquet of pale pink roses in her hands


airplane


A girl in a red dress holding an umbrella.


















“李老太自动洗碗器”


“随便”


“澳门”


“运”
@article{gong2025onereward,
title={OneReward: Unified Mask-Guided Image Generation via Multi-Task Human Preference Learning},
author={Gong, Yuan and Wang, Xionghui and Wu, Jie and Wang, Shiyin and Wang, Yitong and Wu, Xinglong},
journal={arXiv preprint arXiv:2508.21066},
year={2025}
}